TL;DR
- We added
_id as a sort tie breaker to fix non deterministic pagination _id is a metadata field with no doc values. Sorting on it loads everything into JVM heap via fielddata- At scale, this caused JVM to spike to 98–99%, triggered circuit breakers, and flooded us with 429 errors
- The fix: use a properly mapped
keyword field with doc values instead - Lesson: know what lives on heap and what doesn't before you sort on it
Picture This
You've just deployed what looks like a routine fix. A two line change. A sort tie breaker to handle non deterministic pagination. Nothing that would raise an eyebrow in code review.
Minutes after the deploy, your monitoring lights up. JVM pressure is spiking. Errors are flooding in. Your OpenSearch cluster, which was perfectly healthy moments ago, is struggling to stay alive.
You didn't change your data. You didn't change your infrastructure. You added one field to a sort query.
That's exactly what happened to us.
The Change
We had a query sorting results by @timestamp in descending order. The problem: when multiple documents share the same timestamp, their relative order is non deterministic. Paginated results were inconsistent. Documents would appear on different pages across requests.
The standard fix for this is a tie breaker. A secondary sort on a unique field to guarantee consistent ordering. And _id, the document's unique identifier, seemed like the obvious choice.
// Primary sort
{
Field: "@timestamp",
Order: reporting.DESC,
},
// Tie breaker
{
Field: "_id",
Order: reporting.ASC,
},
Clean. Logical. Merged. Deployed.
The Fallout
JVM memory pressure jumped from ~84% to 98–99% almost immediately. The field data cache was consuming heap faster than GC could reclaim it.
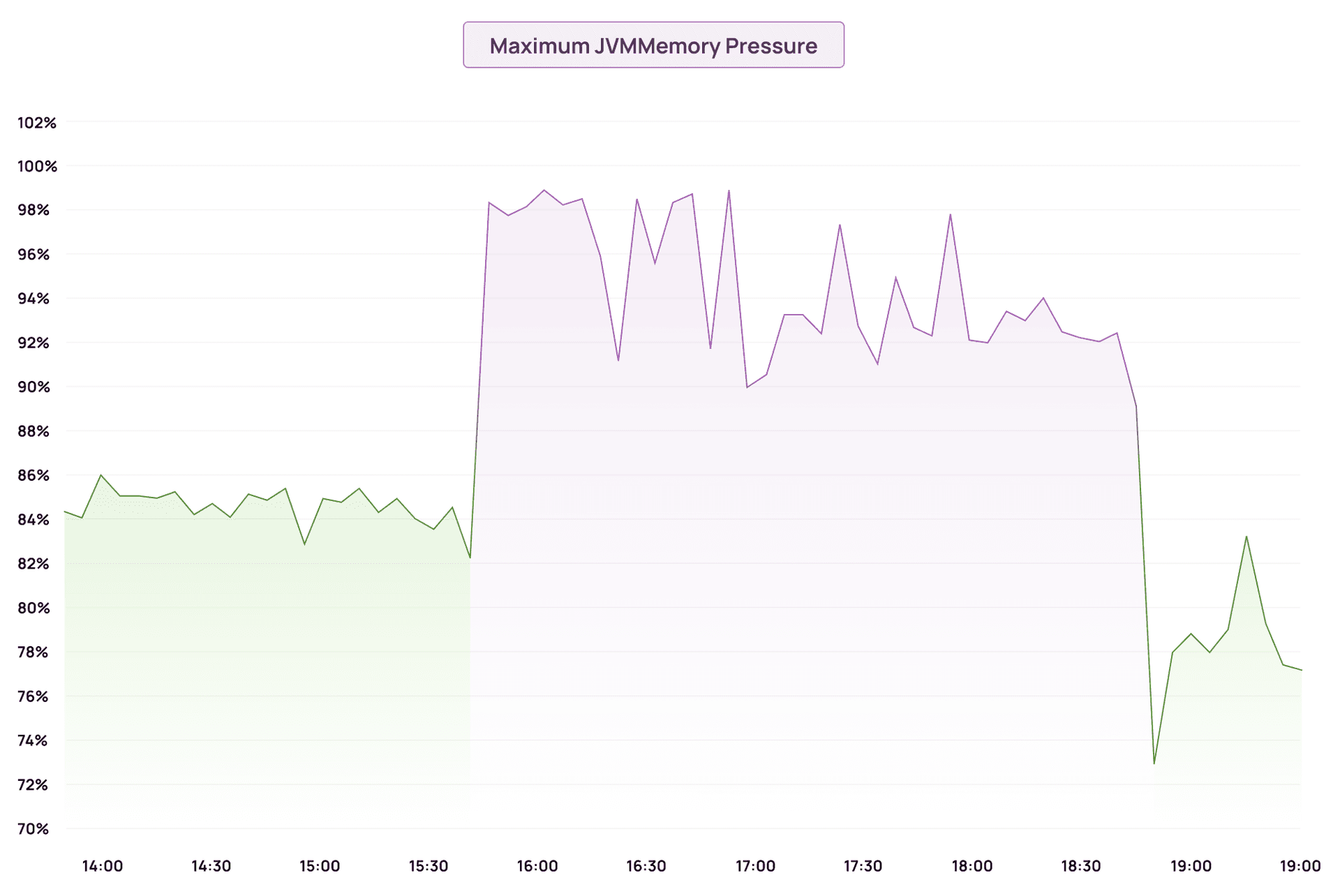
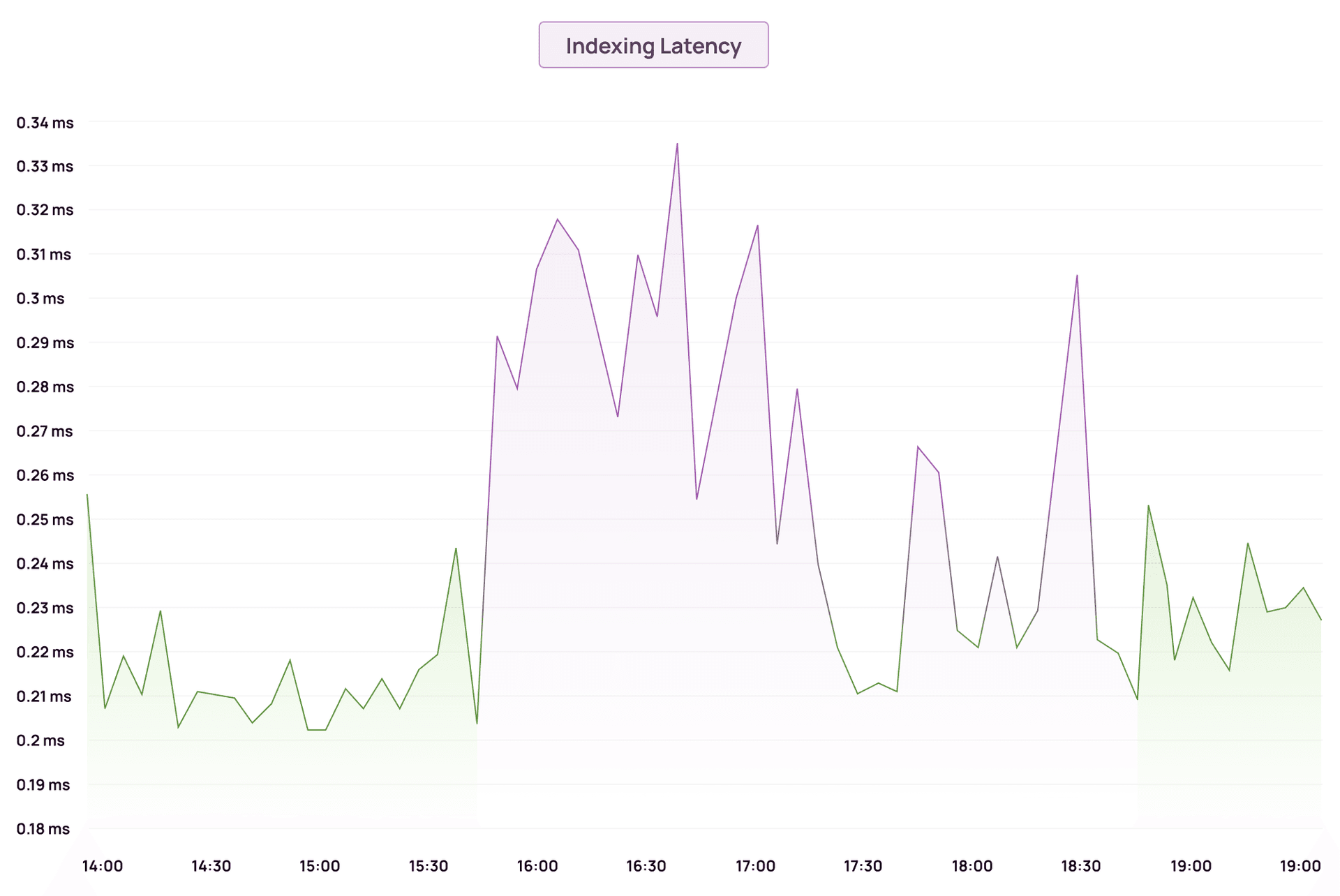
Indexing latency climbed sharply as the JVM spent more time garbage collecting than actually indexing documents.
Then the circuit breakers tripped. At peak, we saw over 4,000 4XX errors in a single minute, almost all of them 429s. Writes were being dropped. Queries were timing out.
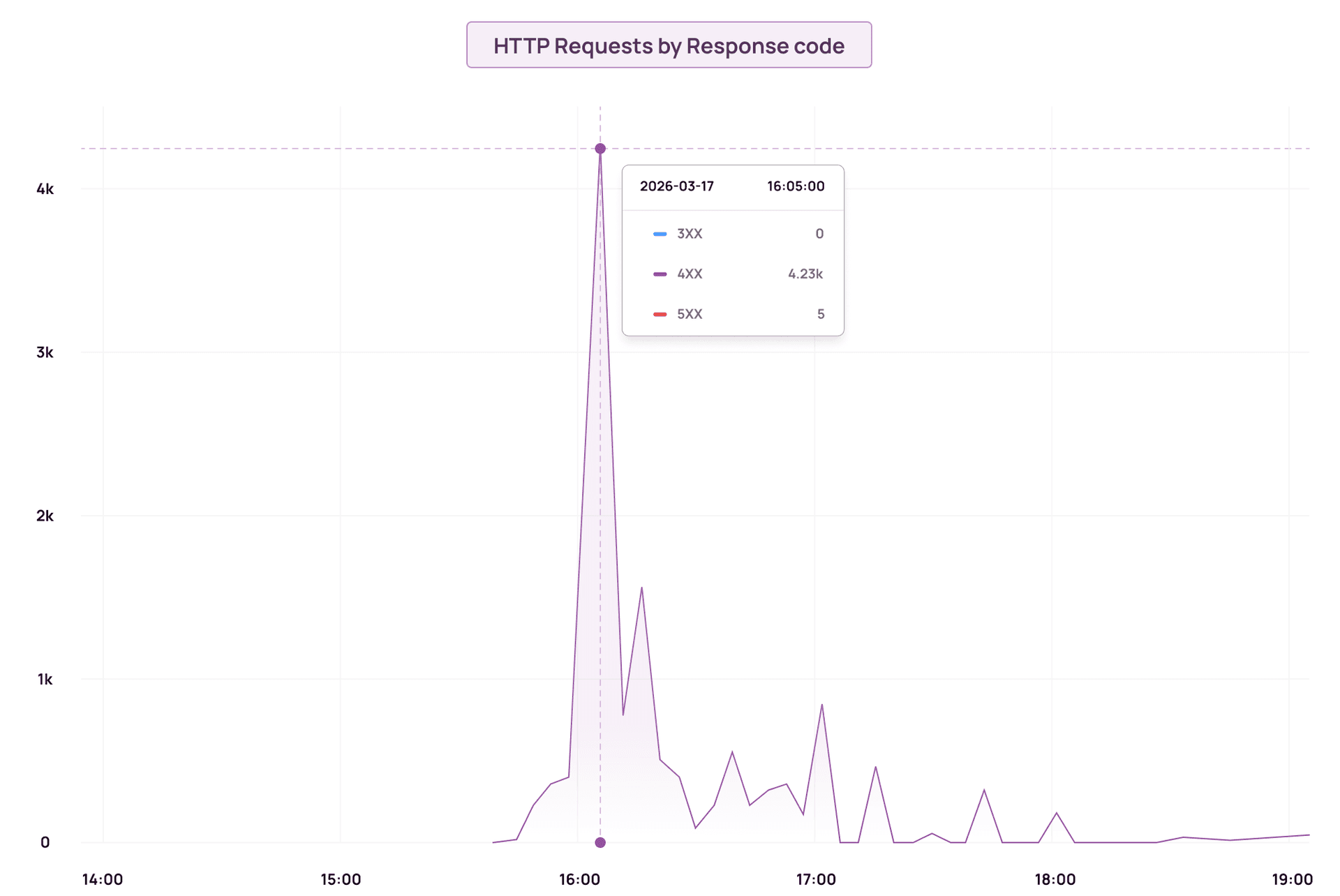
The cluster hadn't changed. Traffic hadn't changed. One field in a sort query did all of this.
That said, despite the cluster struggling under pressure, we didn't lose a single log during the outage. Our internal log-drainer and log-retryer services ensured that any writes rejected by the circuit breakers were retried and eventually delivered. The system was resilient enough to absorb the chaos — nothing was silently dropped.
Why _id Is the Wrong Field to Sort On
_id is a metadata field. It is managed by OpenSearch, not by you.
It exists purely for document identification. It is not indexed for search. It has no doc values. And that last part is what causes the problem.
When OpenSearch sorts on a regular field, say a keyword field, it reads from doc values: an on disk, column oriented structure built at index time. Fast, efficient, zero heap cost.
When OpenSearch needs to sort on _id, there are no doc values to read from. So it falls back to fielddata, a data structure that gets built and held in JVM heap memory at query time.
At small scale, you won't notice this. At production scale, every query that hits that sort is loading data into heap. The fielddata cache grows. GC pressure builds. The circuit breaker, which exists specifically to protect the cluster from memory exhaustion, eventually trips and starts rejecting requests.
OpenSearch's own documentation is explicit about this:
"If you need to sort by document ID, consider duplicating the ID value into another field with doc values enabled."
Joel Dsouza
We were hitting a documented footgun. The kind that doesn't show up in staging, doesn't fail in code review, and only surfaces when real traffic hits it at scale.
The Fix
We already stored an id field in our documents. We just weren't using it for sorting. The fix was replacing _id (metadata, no doc values) with id.keyword (a properly mapped keyword subfield with doc values enabled by default):
{
Field: "@timestamp",
Order: reporting.DESC,
},
{
Field: "id.keyword",
Order: reporting.ASC,
},
With the mapping defined in our index template:
"id": {
"type": "keyword",
"index": false,
"doc_values": false,
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
id.keyword is a keyword type. Keyword fields have doc values enabled by default. Sorting reads from disk, not heap. No fielddata. No memory explosion.
We deployed. JVM came back down. Cluster stabilized.
What This Should Change About How You Think About Mappings
This incident is really about two things: a wrong field choice, and a broader lesson about how OpenSearch physically stores and accesses data.
1. Never sort on _id or other metadata fields
Metadata fields like _id, _index, and _type are managed internally by OpenSearch. They don't have doc values. Sorting on them forces fielddata, and fielddata at scale is a liability. If you need to sort by document ID, store it explicitly in your mapping as a keyword field.
2. Doc values vs fielddata — know the difference

Any field you intend to sort or aggregate on needs doc values. If a field doesn't have them, OpenSearch either refuses to sort on it or falls back to fielddata. Neither of which is what you want in production.
3. Use keyword for fields that don't need full text search
Dynamic mappings are convenient, but they're a trap. OpenSearch will often map string fields as text, which is tokenized and analysed for full text search, but cannot be efficiently sorted or aggregated without a keyword subfield.
For fields like IDs, statuses, categories, and tags, anything where you don't need text search, define them explicitly as keyword in your index templates. You get doc values for free, sorting works correctly, and there's no heap pressure.
Explicit mappings are not overhead. They are the contract between your application and your cluster. Define them upfront, especially in high volume environments.
Wrapping Up
A two line change to a sort query caused a production OpenSearch cluster to spike to near 100% JVM pressure, trip circuit breakers, and drop writes, all because _id doesn't have doc values.
The fix was equally small. But making it required understanding that in OpenSearch, not all fields are equal. Some sort from disk, some sort from heap, and at scale that difference is everything.
Know your mappings. Know your fields. Know what lives on heap and what doesn't.








