What We Do: Real Time Data Access Monitoring with eBPF
Our platform captures data access in real time for AI security and data protection. We track which agents and applications access sensitive data, audit potential exfiltration, detect anomalous access patterns, and discover shadow AI systems touching production databases.
We use eBPF to observe traffic and execution context with near zero deployment friction:
- Universal coverage: Works across data stores by observing traffic and process context, which is critical for discovering shadow AI and monitoring agentic access.
- Protocol agnostic at the transport layer: We observe socket syscalls for all traffic. For TLS, the kernel sees ciphertext, so we additionally instrument common TLS libraries to capture plaintext at the encryption boundary.
- Zero touch deployment: No database plugins, no log parsing, no application changes. This matters when you need coverage for third party tools and fast moving AI apps.
- Runtime visibility: We can attribute access to the process, container, service account, and runtime context behind it, including LLM generated queries and tool based retrieval.
At a high level, we collect a stream of payload fragments plus context (process, connection tuple, timestamps, direction). Userspace reconstructs higher level intents like queries and requests, classifies sensitivity, and correlates them into broader access patterns.
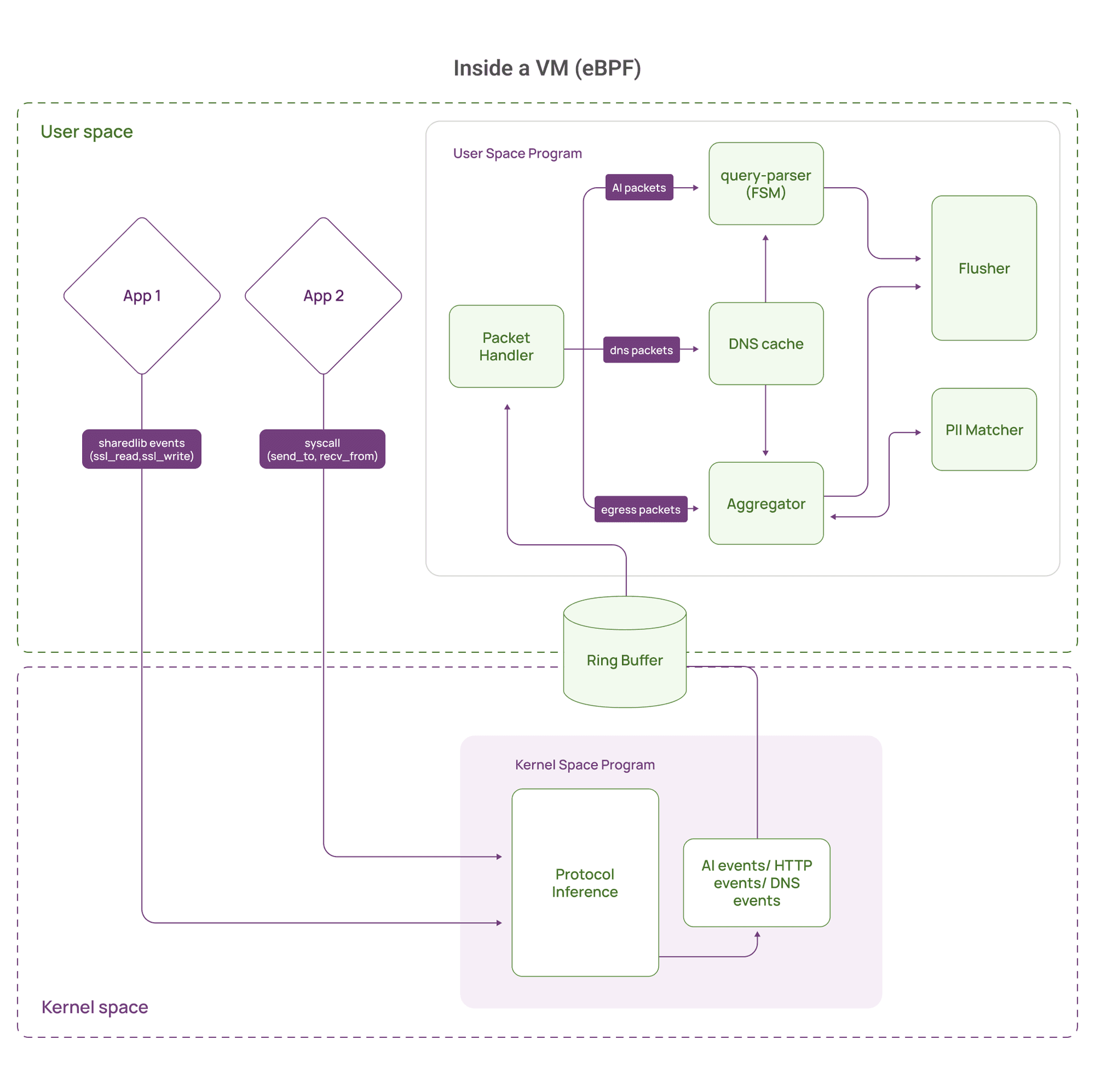
This approach works well, but it creates a class of scaling problems that show up in high throughput systems, especially when TLS is involved.
The Wall: 550 TPS and Dropping Events
We hit a hard ceiling during load testing with a realistic production workload.
Our setup simulated an AI powered customer support system: multiple LLM agents querying a MySQL database over TLS to retrieve customer information, transaction history, and support tickets.
Everything looked fine until we crossed roughly 500 to 600 transactions per second. At that point, loss spiked suddenly.
The culprit was our ring buffer, the fixed size queue used to move events from the kernel to userspace. It was filling faster than userspace could drain it. Once full, telemetry was dropped, and we lost visibility into what the agents were accessing.
For a security monitor, even small drop rates create blind spots. Exfiltration, policy violations, and anomalous access can hide inside the missing slice.
What made this puzzling was the contrast with non TLS traffic. The same workload without TLS ran at 5,500+ TPS with no drops. With TLS enabled, CPU crossed two cores at 500 to 600 TPS. Memory looked fine. Userspace parsing and classification latency looked normal.
So the bottleneck was earlier. It was in how we were packaging and transporting telemetry across the kernel to userspace boundary.
The Investigation: Tracing Ring Buffer Bloat
We added instrumentation to track what was actually consuming ring buffer capacity. That is when it clicked.
With TLS, what you conceptually think of as “one query response” often arrives as many small fragments. Large result sets get split across many syscalls. In our test, typical MySQL TLS response fragments were often 4 to 40 bytes, sometimes smaller.
Those fragments might contain:
- Partial row and field data
- Column metadata and headers
- Small chunks from multi row results
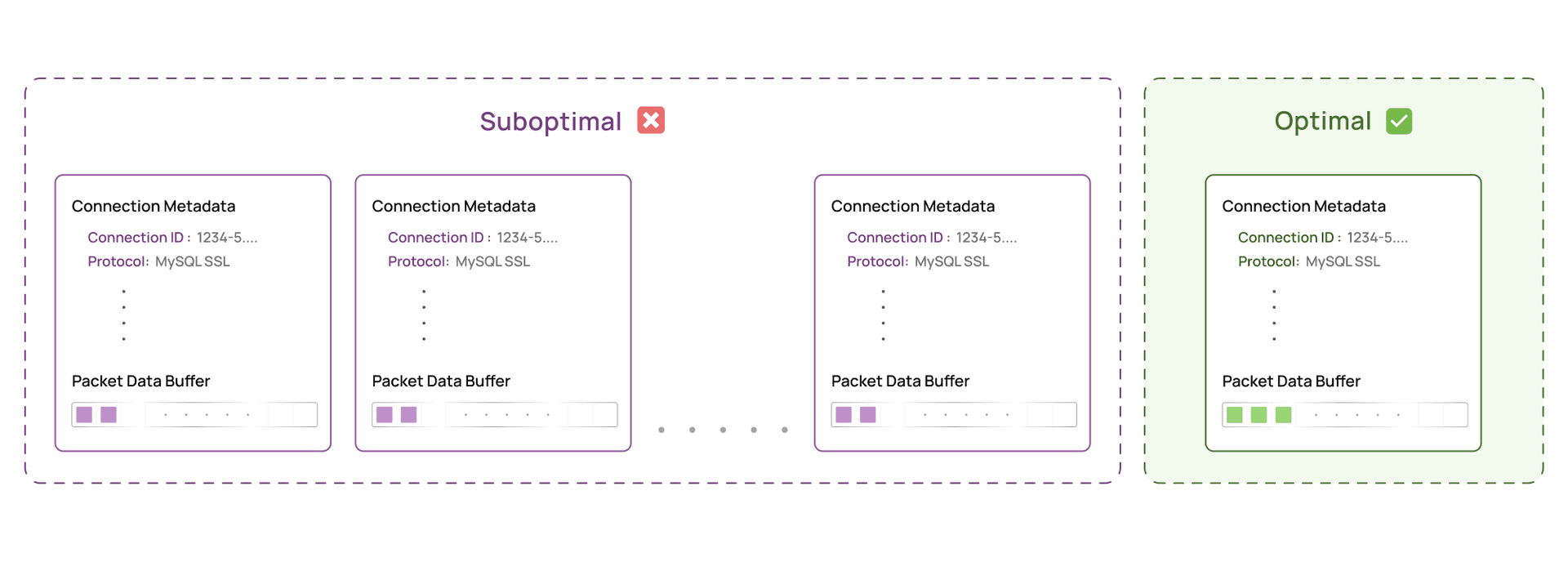
Our program was emitting an event for every fragment. And each event carried:
- About 200 bytes of metadata (connection ID, process and thread IDs, protocol, IPs, timestamps, direction)
- A fixed 1,024 byte payload buffer reserved for the fragment
So a 20 byte fragment reserved roughly 1,224 bytes in the ring buffer. Most of it was padding.
That is the key point. The ring buffer was not full of “data”. It was full of repeated metadata and empty payload space.
At 500 to 600 TPS, we were pushing tens of megabytes per second into the ring buffer, with the bulk being wasted capacity. Once the buffer filled, we dropped events, and lost visibility.
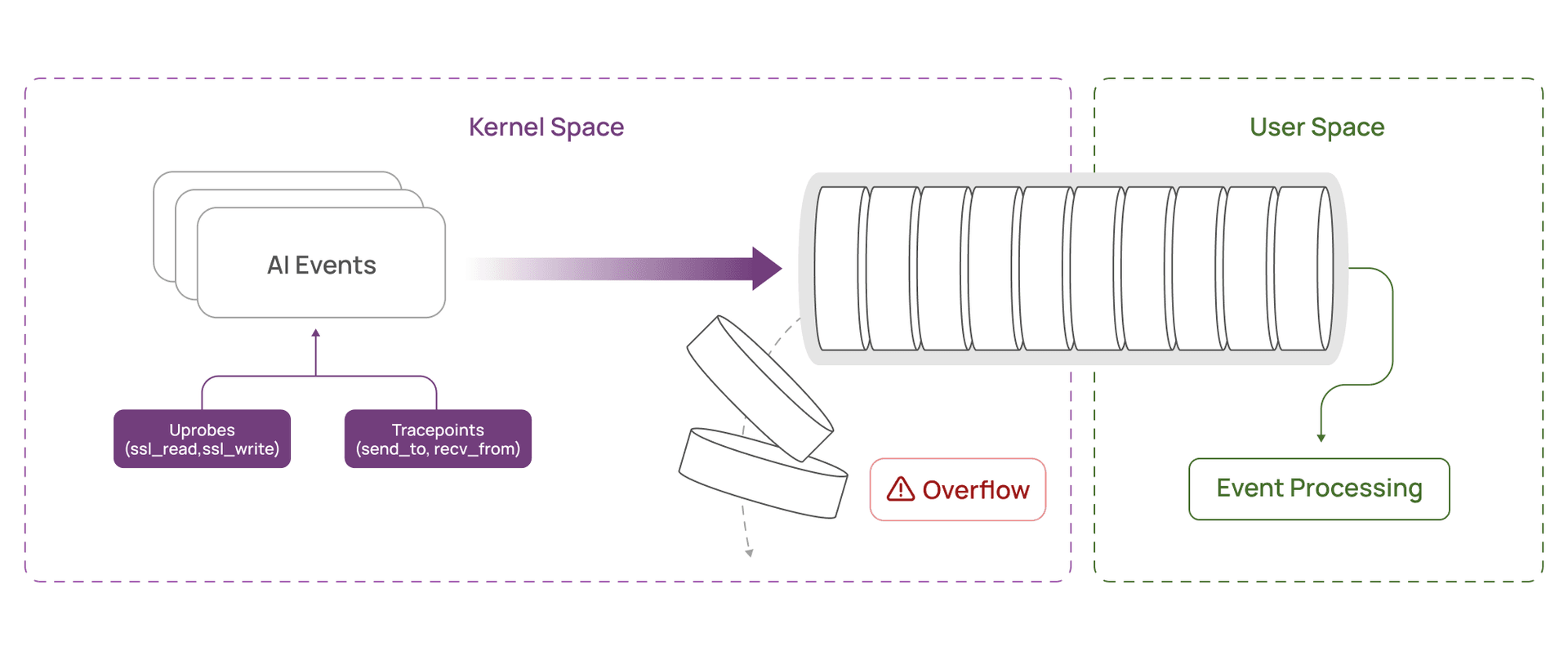
A natural question here is: “Why not use variable sized ring buffer records instead of a fixed 1KB payload?”
Even if we shrink the record to metadata plus fragment_size, we still pay the per fragment cost of metadata and userspace wakeups. The scaling issue was not only bytes. It was also the number of events crossing the boundary.
We needed fewer, denser events.
The Obvious Solution: Accumulate Fragments in Kernel Space
The fix seemed straightforward. Accumulate small fragments per connection in kernel space, then flush in larger chunks.
Instead of sending every 20 byte fragment immediately, we would:
- Maintain a per connection accumulation buffer in kernel space
- Append fragments as they arrive
- Flush to userspace only when we reach a target batch size (for example 1KB), or on context changes
This amortizes fixed overhead. One metadata snapshot can cover dozens of fragments.
In our workload, that shifts the math from:
- Before: 100 fragments × 1,224 bytes ≈ 122KB per query response
- After: 1 batched event × about 1,224 bytes ≈ 1.2KB per query response
Problem solved, right?
Not quite.
The eBPF Verifier: When “Correct” Is Not Enough
In eBPF, you do not just write correct code. You write code the verifier can prove is safe.
The verifier is a kernel component that statically analyzes the program before it is allowed to run. It must be convinced that your program cannot read or write out of bounds, cannot dereference invalid pointers, and cannot loop forever. If it cannot prove safety, your program will not load.
To accumulate fragments, you naturally write code like:
bpf_probe_read_user(&buf[offset], size, src);
offset += size;
A human reads this as safe if you guard it with:
if (offset + size < CAPACITY) {
bpf_probe_read_user(&buf[offset], size, src);
}
But the verifier often cannot retain relationships between variables the way humans do. In many contexts, it treats offset and size as independent unknowns with ranges, and it must be able to prove safety in the worst case.
The “A + B < capacity” Problem
In our case:
offset could be anywhere from 0 to 1023size could be anywhere from 1 to 1024- buffer capacity was 1024
The verifier effectively reasons:
- Worst case
offset = 1023 and size = 1024 offset + size = 2047- 2047 does not fit in a 1024 byte buffer
- Reject
Our runtime checks did not help because the verifier could not prove that the check enforces a safe relationship for all paths.
This is a known limitation and has been discussed widely in eBPF communities. The takeaway is simple: the verifier needs bounds it can prove statically, not bounds you can justify logically at runtime.
The Breakthrough: Make the Buffer Bigger Than You Use
We had two options:
- Reduce the maximum possible ranges of
offset and size so their sum always fits in 1KB - Increase the buffer capacity so the verifier’s worst case sum fits
Option 1 was not realistic for our workload. Fragment sizes vary. Response patterns vary. We needed flexibility.
Option 2 was counterintuitive but effective. We allocated a 2KB buffer to support a 1KB flush size.
- Worst case verifier sum: 1023 + 1024 = 2047
- Buffer size: 2048
- Result: provably safe
We still flush at 1KB. We do not actually try to fill 2KB in normal operation. The extra space exists primarily to satisfy the verifier’s static reasoning.
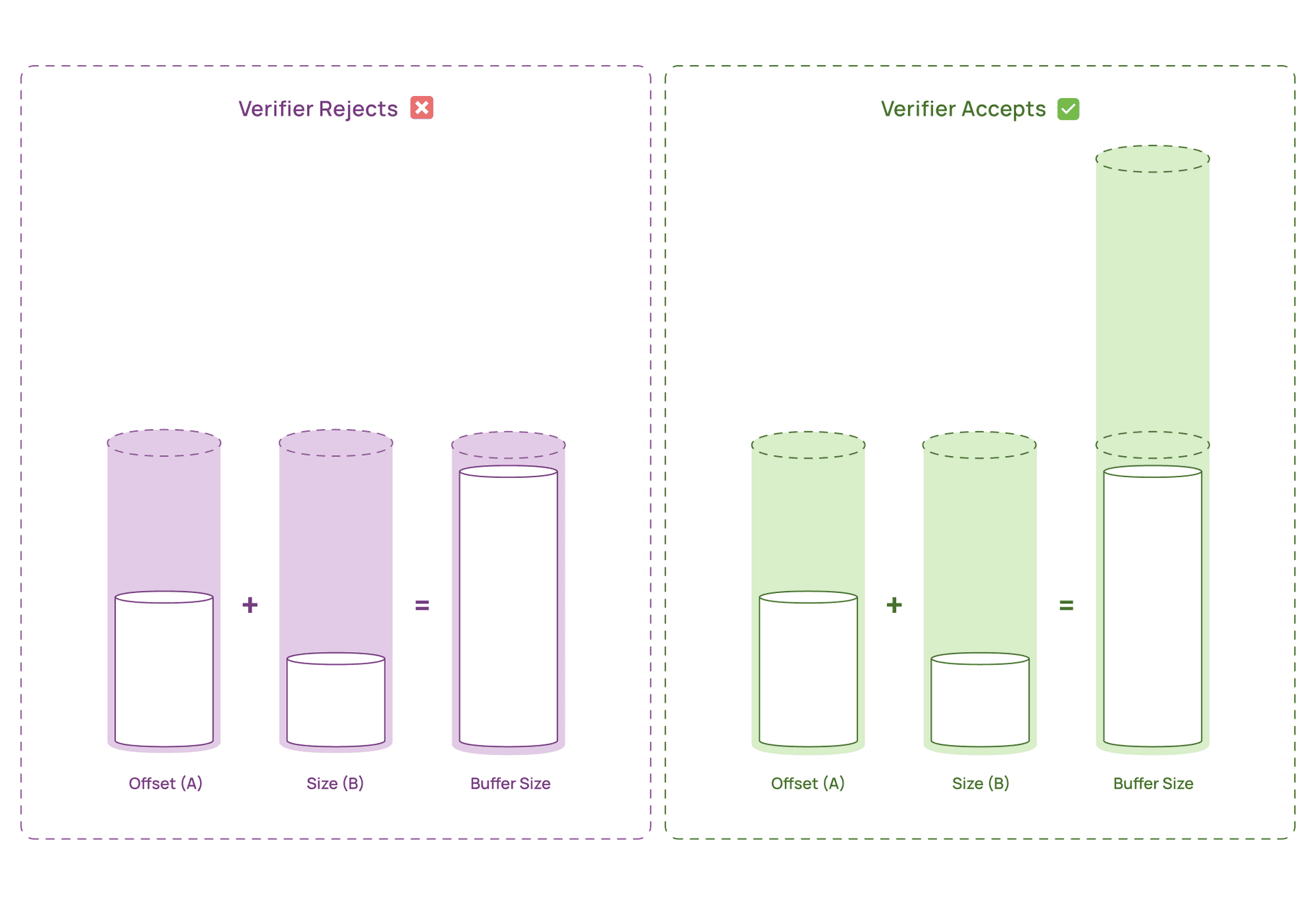
This “over allocate for proof” trade off is often cheap in practice. Even at 10,000 concurrent connections, 2KB per connection is about 20MB of memory, which is typically acceptable on modern hosts. In return, we get stable, lossless telemetry at production throughput.
Additional Verifier Friendly Moves
We also made array offsets trivially provable using masking:
// BUFFER_SIZE must be a power of 2
buf[offset & (BUFFER_SIZE - 1)] = data;
Two important notes:
- This requires
BUFFER_SIZE to be a power of two (1024, 2048, 4096). - In valid execution, our logic keeps
offset within the flush range, so the mask is effectively a no op. It is there to make the bound obvious to the verifier, not to change semantics.
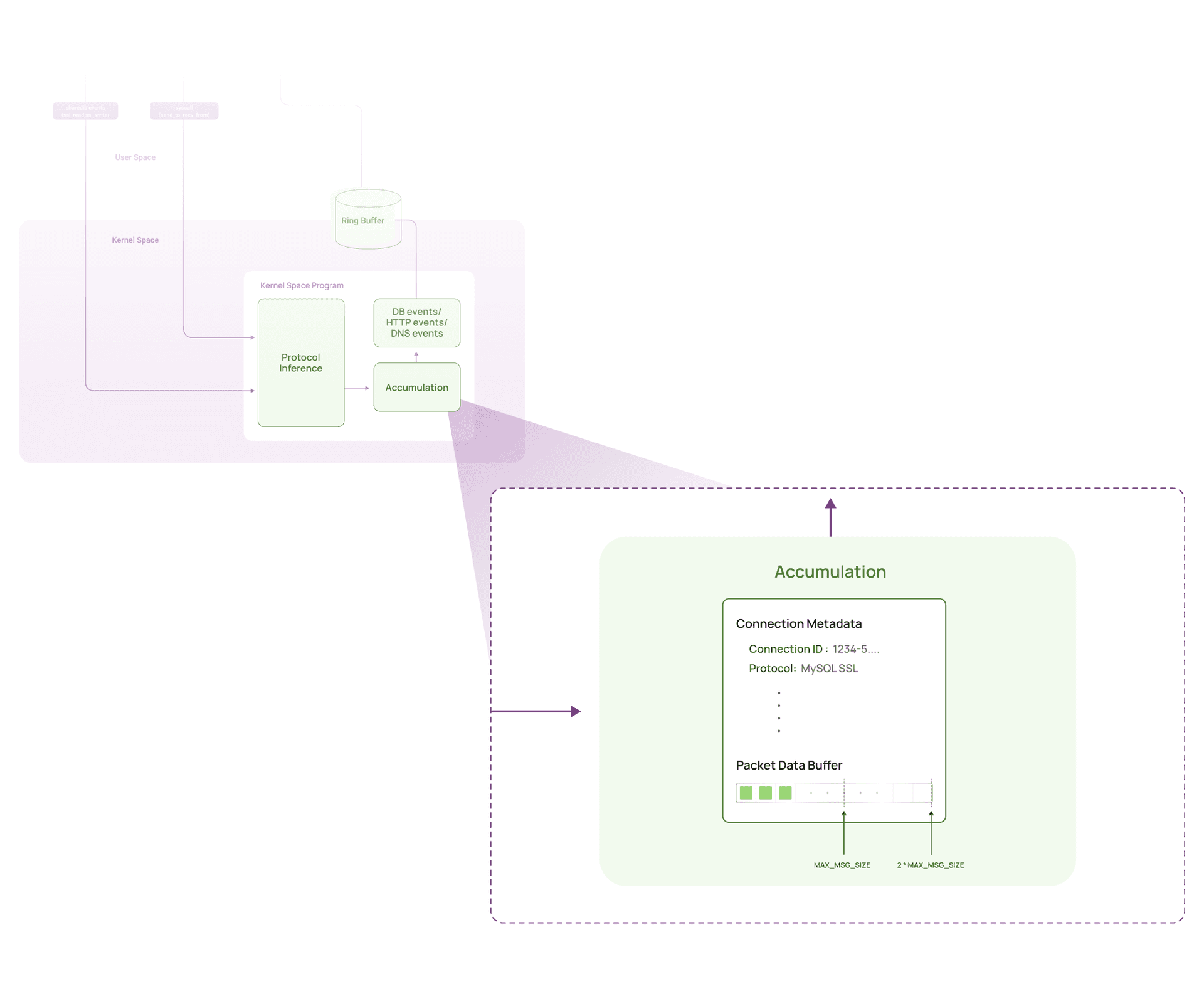
How the Accumulation Works
At a high level, we maintain a per connection accumulator in kernel space. Each accumulator holds:
- A snapshot of security relevant metadata captured once per batch
- Small state about the batch
- The accumulation buffer itself
Per-connection accumulator:
├─ Metadata snapshot (captured once per batch)
│ ├─ Connection ID
│ ├─ Thread ID
│ ├─ Protocol type
│ └─ Traffic direction
├─ Buffer state
│ └─ Current fill level (0 to MAX_FLUSH_SIZE bytes)
└─ Accumulation buffer (2 * MAX_FLUSH_SIZE bytes allocated)
In our implementation:
MAX_FLUSH_SIZE = 1024- Accumulation buffer allocated size is
2048 to satisfy the verifier - We flush to userspace as 1024 byte batches
When a fragment arrives, we look up the accumulator for that connection and append.
If the security context changes mid stream (for example a different thread, direction change, or protocol state change), we flush immediately so each batch stays context consistent.
static __always_inline void on_fragment_captured(
void *ctx,
uint64_t connection_id,
const char *fragment,
uint32_t fragment_size,
struct metadata_t *metadata)
{
// Look up accumulator state
struct accumulator_t *accumulator =
bpf_map_lookup_elem(&accum_map, &connection_id);
if (!accumulator) {
bpf_map_update_elem(&accum_map, &connection_id,
&ZERO_ACCUMULATOR, BPF_ANY);
accumulator = bpf_map_lookup_elem(&accum_map, &connection_id);
if (!accumulator)
return;
}
// Flush when stream context changes
if (stream_context_changed(accumulator, metadata)) {
flush_to_userspace(ctx, accumulator, metadata);
update_accumulator_metadata(accumulator, metadata);
}
uint32_t remaining = fragment_size;
// If closing or fragment too large, flush and send directly
if (metadata->source_fn == CLOSE ||
remaining > MAX_ACCUM_COPY_SIZE) {
flush_to_userspace(ctx, accumulator, metadata);
send_to_userspace(ctx, fragment, fragment_size, metadata);
return;
}
// Flush if accumulator is already full
if (accumulator->fill_level >= MAX_CHUNK_SIZE - 1) {
flush_to_userspace(ctx, accumulator, metadata);
}
// Compute available space in the accumulation window
uint32_t space_available =
(MAX_CHUNK_SIZE - 1) - accumulator->fill_level;
// Compute verifier-safe destination offset
uint32_t safe_offset =
accumulator->fill_level & (MAX_CHUNK_SIZE - 1);
// Compute number of bytes we can safely copy
uint32_t bytes_to_copy = space_available;
if (bytes_to_copy > remaining)
bytes_to_copy = remaining & (MAX_CHUNK_SIZE - 1);
// Extra cap required for older kernels (e.g. RHEL 8, kernel 4.18)
if (bytes_to_copy > MAX_ACCUM_COPY_SIZE)
bytes_to_copy = MAX_ACCUM_COPY_SIZE;
// Copy fragment slice into accumulation buffer
bpf_probe_read_user(
&accumulator->buffer[safe_offset],
bytes_to_copy,
fragment
);
accumulator->fill_level += bytes_to_copy;
remaining -= bytes_to_copy;
// Flush once we reach the flush threshold
if (accumulator->fill_level >= MAX_FLUSH_SIZE) {
flush_to_userspace(ctx, accumulator, metadata);
accumulator->fill_level = 0;
}
// If leftover data remains, flush and send it directly
if (remaining > 0) {
flush_to_userspace(ctx, accumulator, metadata);
send_to_userspace(
ctx,
fragment + bytes_to_copy,
remaining,
metadata
);
}
}
The key insight is structural: we allocate a 2048-byte accumulation buffer, but flush data to userspace using a separate 1024-byte security event.
Before this change, we sent a full 1024-byte security event for every tiny fragment, wasting space and CPU while creating blind spots in AI security monitoring. With accumulation, we pack dozens of fragments into a single comprehensive security event, dramatically reducing ring buffer pressure while maintaining complete visibility into AI agent data access patterns.
Results: About 10x Throughput, Zero Drops
After deploying kernel space accumulation:
Throughput:
- Before: 500-600 TPS (with packet drops)
- After: 5,500+ TPS (no packet drops)
- Improvement: 1000% (yes, ten times better)
CPU Utilization:
- Before: 2+ cores at 500-600 TPS
- After: 1.6 cores at 5,500+ TPS
- Impact: Higher throughput with less CPU
Memory Usage:
- No noticeable change at runtime
- Slight increase for accumulator buffers (~20MB for 10,000 connections)
- Offset by reduced ring buffer pressure and fewer userspace wakeups
The ring buffer went from overflowing at 500 TPS to handling 5,500+ TPS comfortably; enough to monitor dozens of concurrent AI agents accessing sensitive data. The bottleneck was never our data classification or policy enforcement logic: it was the sheer volume of tiny, wasteful security events we were pumping into the ring buffer.
By accumulating fragments before sending, we turned 100 mostly-empty 1KB events into 1 full, information-dense 1KB security event.
And the CPU improvement? That came from reduced context switches and userspace processing. Every ring buffer event triggers a userspace wakeup for security analysis. Fewer events = fewer interruptions = better CPU efficiency = lower cost for comprehensive AI security monitoring.
Why This Matters for Security and beyond?
This problem isn’t tied to database monitoring, a single protocol, or even AI security specifically. It shows up anytime an eBPF program needs to move a high-frequency stream of small, variable-sized payload fragments from kernel space to user space.
You can run into the same bottleneck if you’re using eBPF for:
- Observability or tracing
- Traffic inspection or monitoring
- Any system emitting high-volume, variable-sized events
And it becomes especially painful in AI-heavy workloads, where systems generate thousands of micro-interactions per second, such as:
- AI agents and autonomous systems (tool calls, API calls, data access patterns)
- LLM applications (prompt and response flows, retrieval access, outbound calls)
- RAG systems (auditing which documents and chunks get retrieved)
- Shadow AI discovery (detecting unapproved tools touching production systems)
- Data loss prevention (inspecting sensitive payloads flowing to models or third parties)
In all these cases, fixed per-event overhead (metadata, buffer reservation, userspace wakeups) adds up fast. A naive design can hit throughput limits long before CPU or memory become the issue. The result is usually one of two bad choices: scale back visibility (blind spots) or over-provision infrastructure (cost).
Conclusion: Design for What the Verifier Can Prove
The fix was not faster parsing or better classification. It was changing how telemetry crosses the kernel to userspace boundary.
We got about 10x throughput improvement by accumulating small fragments in kernel space, then flushing dense batches to userspace. The thing that almost blocked us was the verifier. A 1KB accumulation buffer was logically correct, but it was not provably safe under the verifier’s static reasoning. Over allocating the buffer to 2KB made the worst case bounds provable while keeping runtime behavior unchanged.
The broader lesson is simple: in eBPF, safety proof is part of the design. Once we shaped our data layout and control flow around what the verifier can reason about, the accumulation strategy worked exactly as intended, and we regained lossless visibility at production scale.
Thanks for reading. If you are building eBPF based security and observability tools and have your own verifier war stories, we would love to compare notes.







